Reversing the dial: the many faces of gNMI dial-out
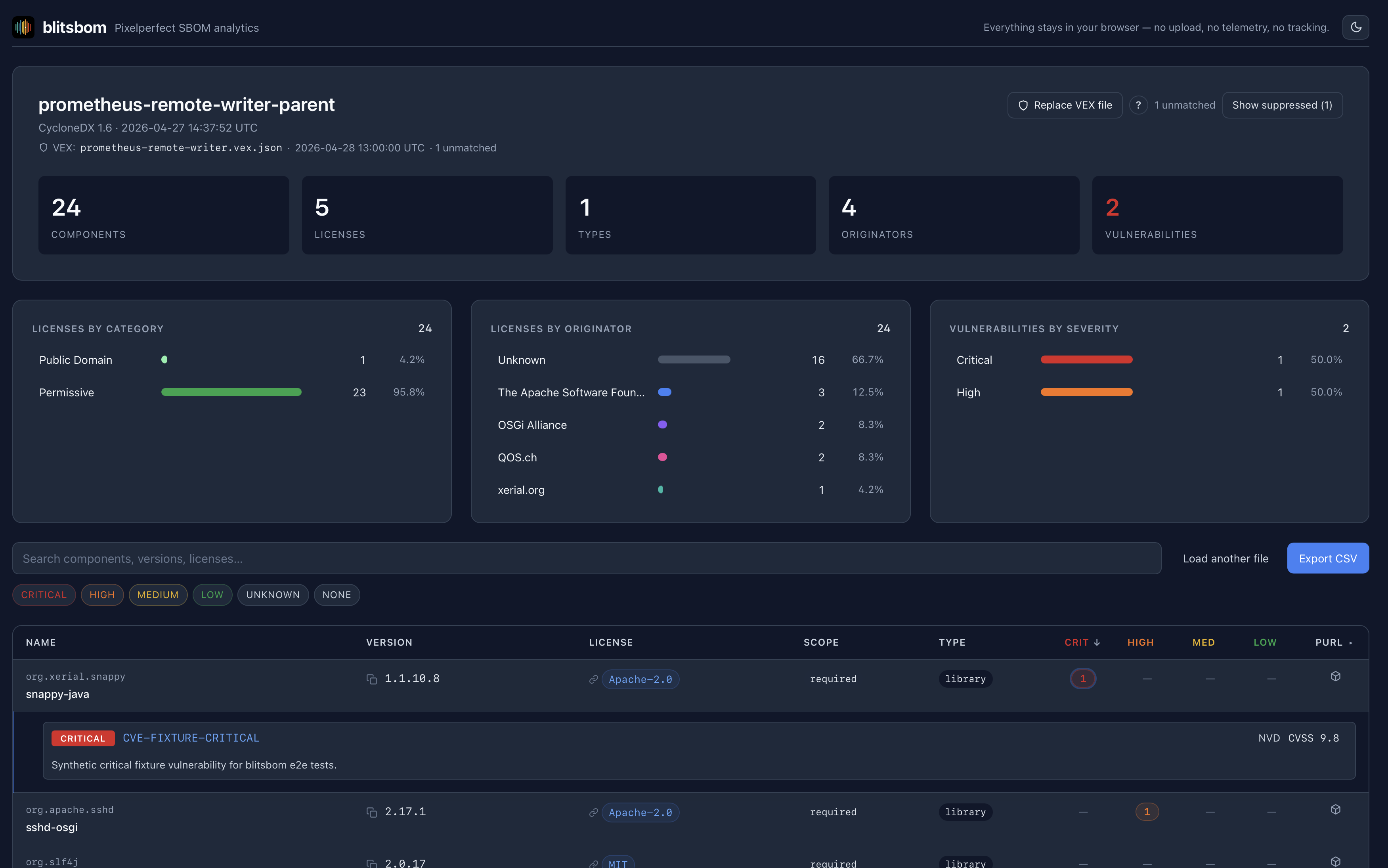
Ask five vendors how they do “gNMI dial-out” and you’ll get five different answers. You’ll find everything a custom gRPC service here, an opaque protobuf envelope there, a generic tunnel over on the standards track. When I started to work on gNMI dial-out in nl6, I wanted the whole map, not just the one corner I’d already implemented. The work with the nl6 simulator forces me to understand the landscape.
The punchline up front, because it reframes everything: gNMI has no dial-out.
Continue reading